|
|
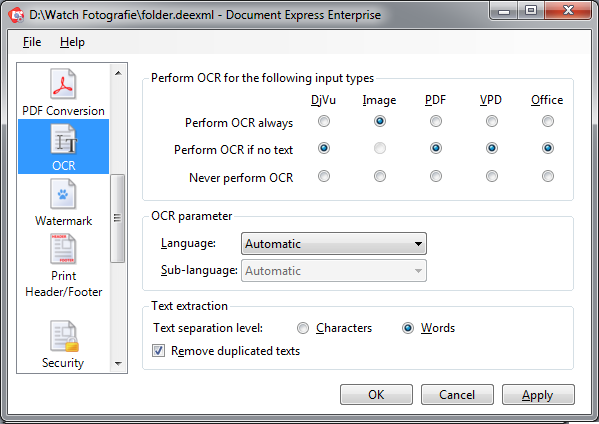
Perform OCR for the following input types - wykonanie rozpoznania optycznego tekstu dla poniższych typów plików i dokumentów : |
 |
DjVu - pliki w formacie DjVu. |
|
|
|
PDF - dokumenty elektroniczne w formacie PDF lub PDF/A. |
|
VPD - pliki skierowane do drukarki wirtualnej. |
|
|
Rodzaj operacji, którą należy wykonać podczas konwersji poszczególnych typów plików i dokumentów : |
|
Perform OCR always - wykonanie rozpoznania optycznego tekstu dla każdego konwertowanego pliku. |
|
Perform OCR if no text - wykonanie rozpoznania optycznego tekstu będzie wykonane tylko dla tych konwertowanych dokumentów, które nie posiadają ukrytej warstwy tekstowej. Ponieważ pliki graficzne nie mogą posiadać ukrytej warstwy tekstowej, użycie tej opcji w ich przypadku, jest bezzasadne. |
|
Never perform OCR - Rozpoznanie tekstu podczas realizacji zadania konwersji nie będzie wykonywane. |
OCR parameter - Parametr języka rozpoznania tekstu. |
|
Language - Pozwala określić nazwę języka, dla którego realizowane będzie rozpoznanie tekstu. Wartością domyślną jest "Automatic". Takie ustawienie oznacza, że nazwa języka zostanie przyjęta w oparciu o język systemu operacyjnego. Jeżeli rozpoznawany jest tekst w innym języku niż język systemu operacyjnego, zaleca się, by został wskazany odpowiednim wyborem z rozwijanej listy. |
Text extraction - zachowanie rozpoznanego lub wyekstrahowanego tekstu w pliku wynikowym : |
|
Text separation level - Opcja określająca precyzję zachowania rozpoznanego tekstu w pliku wynikowym. Operacja OCR, poza rozpoznaniem kolejnych znaków, słów, wierszy,... zachowuje również informacje o położeniu rozpoznanego tekstu w stronie pliku wynikowego. Można wskazać, by operacja OCR realizowana była z najbardziej szczegółowym zachowaniem struktury rozpoznanego tekstu, zachowując informację o położeniu każdego rozpoznanego znaku (opcja "Characters") lub by zachowywane były informacje o położeniu każdego rozpoznanego słowa (opcja "Words"). |
|
Remove duplicated text - Włączenie tej opcji powoduje usuwanie z rozpoznanego tekstu znaków parokrotnie powtórzonych, emitowanych np. z pliku PDF. Opcja jest przydatna zwłaszcza wtedy, gdy w tekście występuje czcionka z atrybutem cieniowania. |




 Zobacz także
Zobacz także






